![]() The Museum of HP Calculators
The Museum of HP Calculators
by Stanley M. Blascow, Jr. and James A. Donnelly
Fitting OBSERVED DATA to a mathematical model and finding the optimum values for a multivariable function are common engineering needs. To aid the engineer in performing such calculations, a special plug-in ROM module was developed for the HP-71B Computer. The Curve Fit Pac is a hybrid of BASIC and assembly language programs stored in a 32K-byte ROM. Two general capabilities are provided:
The Curve Fit Pac's powerful curve-fitting capabilities are based on a minimization algorithm known as the Fletcher-Powell method.1 For optimization, this algorithm is applied to the function whose maxima and minima are to be found. For curve-fitting, the algorithm is used to minimize a form of x2 (chi-square) function defined by
x2(P) = Σi=1..m[(Fi-yi)/wi]2
where fi is the value of F for the ith data point and the current parameter matrix iterate (i.e., estimate) P. The values wi are user-supplied weighting factors and are ideally equal to the standard deviations of the dependent variables yi if known. Thus reliable data (small standard deviation) can be weighted more heavily. With equal weights, this equation corresponds to the function that is minimized in the usual least-squares curve-fit method.
A friendly user interface provides for entry, editing, storage, and viewing of data. Options for storing the data files to mass storage devices and for printing the data and results are provided. The user can select one of the 84 built-in mathematical models, or if necessary, can write a BASIC subprogram that specifies a desired model.
Functions not adversely affected by speed considerations (e.g., user interface and I/O) are written in BASIC, while all of the numerical calculations are done in assembly language (to full 15-digit precision) by callable binary subprograms. The seven binary subprograms can be called directly by the user. This permits the user interface to be copied into the HP-71B's RAM and customized while still using the ROM-based numeric routines.
The binary subprograms are called with parameters (both arrays and simple variables) passed by reference. Results are passed back to the calling routine through the passed parameters. All of the binary routines mentioned below except POLY and LIN use temporary system buffers during execution to store intermediate results. This memory is returned for system use on exit from the subprogram.
The Fletcher-Powell method is a gradient-based iterative method to find the location of a local minimum of a function of k variables.* That is, F(X) = F(x1, x2, . . ., xk). In this application, k cannot exceed 20. While the Fletcher-Powell method is designed for minimization, the function G = -F is used for maximization.
Given an initial guess for the location X = P = [p1, p2, . . . ., pk]T of a local minimum, the algorithm produces the next guess P', obtained as the result of a "search" along a specified ray emanating from P in k-space. The manner in which the search direction vector S' = P' - P is determined distinguishes this method from other similar methods. Initially, S' is in the direction of steepest descent (fine direction in which P should be changed to cause the most rapid decrease in F). This direction is the negative gradient of F at P. Subsequent iterations use a modified search direction based on "historical" data kept in a k × k matrix H. This can substantially reduce the number of iterations near critical points. Letting S = S'/||S'|| (S' normalized to a unit vector), the current iteration is reduced to a one-dimensional minimization of F along the ray P + tS for t>0 (t is the step size). This portion of the solution, called LINE-SEARCH, is not part of the Fletcher-Powell algorithm and is implementation-dependent.
The overall procedure terminates successfully when the gradient at the current iterate matrix P achieves a norm less than a user-specified limit called Grad Limit. This corresponds roughly to the graph of F being sufficiently flat (approaching a minimum) at that location. The procedure terminates unsuccessfully if this condition has not been achieved and the number of iterations exceeds another user-specified limit called No. Iterations. See the box on this page for an example of an optimization problem.
The task for the LINE-SEARCH portion of the OPTIMIZE subroutine is to minimize h(t) = F(P + tS) for t>O. The procedure used is a modified cubic fit along the search vector to establish t. The procedure begins by establishing a reasonable search interval [t0,t2]. Let m(t) = the derivative of in(t) and use the notation:
Initially t0 = 0, so that h0 and m0 < 0 are known. After a reasonable guess for t2, h2 and m2 are obtained by sampling. The gradient of F is available from the sampling so that the derivative m(t) can be computed as the dot product:
m(t) = [ F(P + tS) ]T
F(P + tS) ]T  S
S
The primary goal is to achieve a sampling interval [t0, t2 in which m2 > 0 (corresponding to a sign change in the derivative). When this is achieved,** t1--the location of the minimum of a cubic that agrees with h and m at the endpoints--is computed. The values of h1 and ml are computed and if satisfactory, *** the LINE-SEARCH procedure terminates and P' is established as P + t1S. If unsatisfactory, results h1 and m1 are used to establish a new sampling interval (shifted, expanded, or contracted) and the process continues. The procedure terminates unsuccessfully if a user-supplied limit labeled No. Tries is exceeded.
How to handle errors, which models to select, and how to set up the working environment and user interface were some of the design issues that had to be resolved. For example, to eliminate leaving a user deep within the binary software with no way to recover when an error occurs, a clean interface to the binary subprograms is needed. This is provided by returning to the top program level when an error or exception occurs, with a passed condition code indicating the nature of the error or exception condition.
The models were selected from a survey of published libraries and potential users. The models are provided as BASIC subprograms, with the exception of the polynomial and linear models, which are written in assembly language as binary subprograms.
The architecture of the HP-71B presented many special features for the design of the user interface, in that it has the personality of a calculator, yet the capability of many desktop computers The user interface is designed to work with multiple files in memory and on mass storage media. The complex procedures often found on larger computers are reduced to simple keystroke procedures that maximize the utility of each keystroke. Functions can be selected with single keystrokes, and entry of numbers is simplified by providing default answers in the display--usually the previous entry for the same question.
While the curve-fit programs are designed to work in a stand-alone environment, the addition of an 82401A HP-IL Interface Module to the HP-71B permits the use of video interfaces, printers, and external mass storage devices. The programs CFIT and OPTIMIZE are designed to alter the nature of the user interface, the questions asked, and the reporting procedures automatically to conform to the current configuration of the HP-71B in the most efficient manner.
Testing this product proved to be a challenge for a variety of reasons. First, the numerical computation routines are written in assembly language, using the internal 15-digit math routines of the HP-71B. Because of the iterative nature of the Fletcher-Powell and CFIT routines, and the special LINE-SEARCH algorithm, a suitable reference for the results was not to be found. As a result, a software debugger was used to step through the calculations manually, permitting verification of intermediate results kept in system buffers.
The volume of intermediate results to check is extremely large. For example, consider the case where a curve is being fit with a user-written model that has three parameters and does not compute the gradient. Calculation of x2 and the gradient of x2 will require 80 calls to the user's model if there are 20 data points. If there are four samples taken per iteration of the main calculation loop, a single iteration will require 320 calls to the user's model!
Second, the user interface programs CFIT and OPTIMIZE provide a protective "shell" against invalid data for the binary programs. Because the user may write programs to call the binary subprograms, the error-trapping had to be checked thoroughly. This was done by writing a series of interface programs to simulate calls by user programs.
Third, the HP-71B implements the IEEE proposal for handling math exceptions. All programs, BASIC or assembler, had to be tested to ensure that overflow, underflow, and extended default numbers such as Inf (infinity) and NaN (not-a-number) work properly. The complex data types provided by the HP-71B's Math Pac also had to be tested.
Fourth, the HP-71B's operating system allows the user to select settings not usually possible on other computers, including key redefinitions, display speed, width settings, numeric display modes, maintainence of global variables (analogous to storage registers in a calculator), flags, and files. This working environment is very important to people who use their portable machines daily. The CFIT and OPTIMIZE programs alter many of these system settings during the course of execution, but restore the settings upon exit. Extensive testing was done to ensure that this working environment was preserved under all conditions. The functionality of the user interface was extensively evaluated and optimized for use in the portable environment.
Fifth, the memory in the HP-71B can be managed in a number of different ways. It is possible to fill the memory with files until there are just a few bytes left. All of the above issues had to be tested under extremely low available memory conditions to ensure that errors would not cause loss of data.
Sixth, testing the curve-fitting capability required known data. A BASIC tool was developed to produce data whose dependent variables were normally distributed about a selected model with known parameters. The independent variables were selected at random from specified ranges. This allowed comparison between the parameters used to generate the data and the model parameters generated by the Curve-Fit Pac.
Finally, writing the subprograms for the MODELS library involved deriving the partial derivatives for each model, leaving ample room for error. The equations and their implementation were reviewed manually and with the assistance of a symbolic math package running on a larger computer system.
1. R. Fletcher and M.J.D. Powell, "A Rapidly Convergent Descent Method for Minimization," Computer Journal July 1963.
*Editor's note: In this discussion, the prime notation for P and S indicates successive values, not derivatives.
**It is possible that this cannot be achieved.
***Satisfactory is defined as when h, < min h0, h2). Thus, no effort or sampling time is expended in an attempt to improve t,. Instead, there is a rapid return to the Fletcher-Powell algorithm where a new search direction is chosen.
You are designing a box that will be, used to mail widgets. You want the box to have dimensions that will contain the largest volume of widgets while still being acceptable for shipment by the postal carrier. The postal restrictions stipulate that the sum of the length and girth (perimeter of the cross section) cannot exceed 1 00 centimeters. Referring to Fig. 1, and since you will have maximum volume when the length plus girth equals 100, you can use the following equations:
L + (2W + 2H) = 100
Volume V = WHL = WH(100 - 2H - 2W) (1)

All dimensions must be greater than 0, so you can impose the additional constraints: W + H < 50, W > 0, and H > 0.
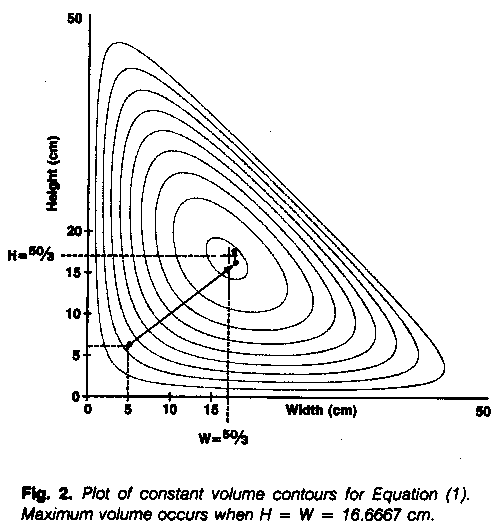
A plot of the contours of the function V in the W-H plane is shown in Fig. 2. Using the default values for gradient limit, number of LINE-SEARCH tries, and number of iterations, and given an initial guess of 5 for W and 6 for H, the OPTIMIZE procedure proceeds on the path shown in Fig. 2 to the final answers of W = 16.6667 cm, H = 16.6667 cm, and V = 9259.259 cm2. L is then found from the equation V = VHL to be 33.3333 cm.
![]() Go back to the HP Journal library
Go back to the HP Journal library
![]() Go back to the main exhibit hall
Go back to the main exhibit hall